NVIDIA GPU Operator를 사용하면 Kubernetes 클러스터에서 GPU 드라이버, 쿠버네티스 구성 요소, NVIDIA 툴킷을 자동으로 설정할 수 있습니다. 이 가이드에서는 RTX 3060을 사용하는 환경에 맞춰 GPU Operator를 배포하는 방법을 설명합니다.
NVIDIA GPU Operator 배포 준비
Helm Repo 추가
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm repo list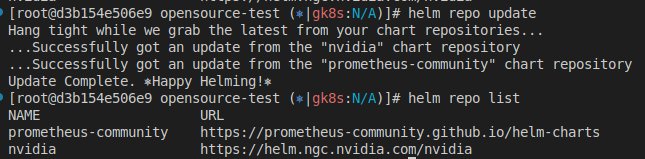
Helm Chart 검색
helm search repo nvidia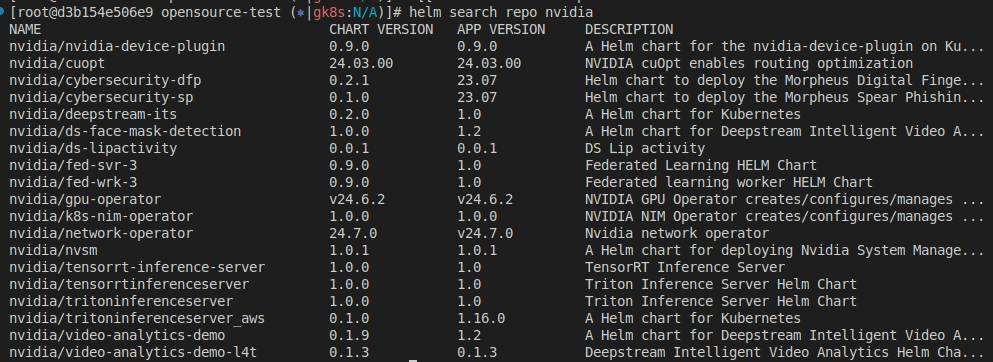
Helm Chart 다운로드
# Download helm chart
helm pull nvidia/gpu-operator --untarHelm Chart Values.yaml 수정
내용을 상세히 살펴보기위해 분할하여 작성하였습니다.
설명이 필요하다 생각되는 부분은 한글 주석 첨부하였습니다.
# Default values for gpu-operator.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
platform:
openshift: false
nfd:
enabled: true
nodefeaturerules: false
psa:
enabled: false
cdi:
#enabled: false
#default: false
enabled: true
default: true
# cdi.enabled: true 기능이 활성화됩니다. 데이터 볼륨과 외부 스토리지 연동 기능을 사용할 수 있습니다.
# cdi.default: true가 기본 데이터 인터페이스로 설정됩니다. CDI를 사용하는 파이프라인이 기본값으로 생성되며, 모든 워크로드가 CDI를 통해 데이터를 관리하게 됩니다.
# 기본적으로 CDI 활성화만으로 Kubeflow와 Kubernetes 내에서 PVC 생성 및 볼륨 관리는 가능해집니다.
# 하지만 외부 스토리지(AWS S3, GCP, NFS 등)를 연동하려면 StorageClass 정의, PVC 생성, 그리고 인증 정보 설정이 필요합니다.
# 만약 단순한 로컬 PVC 사용으로 충분하다면, 큰 추가 작업 없이 CDI 활성화만으로도 바로 활용할 수 있습니다.
# Kubeflow 환경에 외부 스토리지 연동을 계획하고 있다면, 스토리지마다 요구되는 설정 과정을 따라야 합니다.
sandboxWorkloads:
enabled: false
defaultWorkload: "container"
hostPaths:
# rootFS는 호스트의 루트 파일 시스템으로 가는 경로를 나타냅니다.
# 이것은 호스트 파일 시스템과 상호 작용해야 하는 구성 요소에서 사용됩니다.
# 따라서 이것은 chroot 가능한 파일 시스템이어야 합니다.
# 예로는 MIG Manager와 Toolkit Container가 있으며, 이는
# systemd 서비스를 중지, 시작 또는 다시 시작해야 할 수 있습니다.
rootFS: "/"
# driverInstallDir represents the root at which driver files including libraries,
# config files, and executables can be found.
# driverInstallDir는 라이브러리, 구성 파일 및 실행 파일을 포함한 드라이버 파일을 찾을 수 있는 루트를 나타냅니다.
driverInstallDir: "/run/nvidia/driver"daemonsets:
labels: {}
annotations: {}
priorityClassName: system-node-critical
tolerations:
- key: nvidia.com/gpu
operator: Exists # Node Taint의 Key만 맞으면 배포.
effect: NoSchedule
# configuration for controlling update strategy("OnDelete" or "RollingUpdate") of GPU Operands
# note that driver Daemonset is always set with OnDelete to avoid unintended disruptions
updateStrategy: "RollingUpdate"
# configuration for controlling rolling update of GPU Operands
rollingUpdate:
# maximum number of nodes to simultaneously apply pod updates on.
# can be specified either as number or percentage of nodes. Default 1.
maxUnavailable: "1"
validator:
repository: nvcr.io/nvidia/cloud-native
image: gpu-operator-validator
# If version is not specified, then default is to use chart.AppVersion
#version: ""
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
args: []
resources: {}
plugin:
env:
- name: WITH_WORKLOAD
value: "false" # 주의: "true"로 설정하면 설치된 드라이버와 컨테이너가 실제 GPU 워크로드를 제대로 처리하는지 확인하는 테스트를 포함할 수 있습니다.
컨트롤 플레인에 배포되어야 하므로 toleration을 넣어주는 부분이 있습니다.
컨트롤 플레인의 Taint와 비교해봅니다.

operator:
repository: nvcr.io/nvidia
image: gpu-operator
# If version is not specified, then default is to use chart.AppVersion
#version: ""
imagePullPolicy: IfNotPresent
imagePullSecrets: []
priorityClassName: system-node-critical
#defaultRuntime: docker
defaultRuntime: containerd # 쿠버네티스 환경의 런타임에 맞추어줌.
runtimeClass: nvidia
use_ocp_driver_toolkit: false
# cleanup CRD on chart un-install
cleanupCRD: false
# upgrade CRD on chart upgrade, requires --disable-openapi-validation flag
# to be passed during helm upgrade.
upgradeCRD: false
initContainer:
image: cuda
repository: nvcr.io/nvidia
version: 12.6.1-base-ubi8
imagePullPolicy: IfNotPresent
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Equal"
value: ""
effect: "NoSchedule"
annotations:
openshift.io/scc: restricted-readonly
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: "node-role.kubernetes.io/master"
operator: In
values: [""]
- weight: 1
preference:
matchExpressions:
- key: "node-role.kubernetes.io/control-plane"
operator: In
values: [""]/
logging:
# Zap time encoding (one of 'epoch', 'millis', 'nano', 'iso8601', 'rfc3339' or 'rfc3339nano')
timeEncoding: iso8601 # 2021-01-01T00:00:00Z (ISO 표준)
# epoch >> 유닉스 시간(초)로 기록 1609459200 (2021-01-01 00:00:00 UTC)
# Zap Level to configure the verbosity of logging. Can be one of 'debug', 'info', 'error', or any integer value > 0 which corresponds to custom debug levels of increasing verbosity
level: info
# Development Mode defaults(encoder=consoleEncoder,logLevel=Debug,stackTraceLevel=Warn)
# Production Mode defaults(encoder=jsonEncoder,logLevel=Info,stackTraceLevel=Error)
develMode: false
resources:
limits:
cpu: 500m
memory: 350Mi
requests:
cpu: 200m
memory: 100Mi
mig:
strategy: single # rtx3060은 mig가 지원되지 않음 하나의 GPU를 단일 인스턴스로 사용합니다. 즉, MIG를 사용하지 않거나 기본 GPU 전체를 단일 워크로드에 할당합니다.드라이버는 호스트에 설치하였으므로 비활성합니다.
driver:
enabled: false # host에 이미 설치하였음.
nvidiaDriverCRD:
enabled: false
deployDefaultCR: true
driverType: gpu
nodeSelector: {}
useOpenKernelModules: false
# use pre-compiled packages for NVIDIA driver installation.
# only supported for as a tech-preview feature on ubuntu22.04 kernels.
usePrecompiled: false
repository: nvcr.io/nvidia
image: driver
version: "550.90.07"
imagePullPolicy: IfNotPresent
imagePullSecrets: []
startupProbe:
initialDelaySeconds: 60
periodSeconds: 10
# nvidia-smi can take longer than 30s in some cases
# ensure enough timeout is set
timeoutSeconds: 60
failureThreshold: 120
rdma:
enabled: false
useHostMofed: false
upgradePolicy:
# global switch for automatic upgrade feature
# if set to false all other options are ignored
autoUpgrade: true
# how many nodes can be upgraded in parallel
# 0 means no limit, all nodes will be upgraded in parallel
maxParallelUpgrades: 1
# maximum number of nodes with the driver installed, that can be unavailable during
# the upgrade. Value can be an absolute number (ex: 5) or
# a percentage of total nodes at the start of upgrade (ex:
# 10%). Absolute number is calculated from percentage by rounding
# up. By default, a fixed value of 25% is used.'
maxUnavailable: 25%
# options for waiting on pod(job) completions
waitForCompletion:
timeoutSeconds: 0
podSelector: ""
# options for gpu pod deletion
gpuPodDeletion:
force: false
timeoutSeconds: 300
deleteEmptyDir: false
# options for node drain (`kubectl drain`) before the driver reload
# this is required only if default GPU pod deletions done by the operator
# are not sufficient to re-install the driver
drain:
enable: false
force: false
podSelector: ""
# It's recommended to set a timeout to avoid infinite drain in case non-fatal error keeps happening on retries
timeoutSeconds: 300
deleteEmptyDir: false
manager:
image: k8s-driver-manager
repository: nvcr.io/nvidia/cloud-native
# When choosing a different version of k8s-driver-manager, DO NOT downgrade to a version lower than v0.6.4
# to ensure k8s-driver-manager stays compatible with gpu-operator starting from v24.3.0
version: v0.6.10
imagePullPolicy: IfNotPresent
env:
- name: ENABLE_GPU_POD_EVICTION
value: "true"
- name: ENABLE_AUTO_DRAIN
value: "false"
- name: DRAIN_USE_FORCE
value: "false"
- name: DRAIN_POD_SELECTOR_LABEL
value: ""
- name: DRAIN_TIMEOUT_SECONDS
value: "0s"
- name: DRAIN_DELETE_EMPTYDIR_DATA
value: "false"
env: []
resources: {}
# Private mirror repository configuration
repoConfig:
configMapName: ""
# custom ssl key/certificate configuration
certConfig:
name: ""
# vGPU licensing configuration
licensingConfig:
configMapName: ""
nlsEnabled: true
# vGPU topology daemon configuration
virtualTopology:
config: ""
# kernel module configuration for NVIDIA driver
kernelModuleConfig:
name: ""Tookit 구성 설정
containerd를 런타임으로 사용시 추가 환경정보설정이 필요합니다.
toolkit:
enabled: true
repository: nvcr.io/nvidia/k8s
image: container-toolkit
version: v1.16.2-ubuntu20.04
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: # containerd사용시 적용
- name: CONTAINERD_CONFIG
value: /etc/containerd/config.toml
- name: CONTAINERD_SOCKET
value: /run/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: "true"
resources: {}
installDir: "/usr/local/nvidia"아래 내용은 host의 config.toml수정하는 내용이지만, 제외 하고 설치 합니다.
컨테이너에서 nvidia-smi명령이 동작안할때 적용합니다.
# 기본 설치시 설치하지 않고 진행.
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/local/nvidia/bin/nvidia-container-runtime"차례대로 내용을 검토하며 진행합니다.
devicePlugin:
enabled: true
repository: nvcr.io/nvidia
image: k8s-device-plugin
version: v0.16.2-ubi8
imagePullPolicy: IfNotPresent
imagePullSecrets: []
args: []
env:
- name: PASS_DEVICE_SPECS
value: "true"
- name: FAIL_ON_INIT_ERROR
value: "true"
- name: DEVICE_LIST_STRATEGY
value: envvar
- name: DEVICE_ID_STRATEGY
value: uuid
- name: NVIDIA_VISIBLE_DEVICES
value: all
- name: NVIDIA_DRIVER_CAPABILITIES
value: all
resources: {}
# Plugin configuration
# Use "name" to either point to an existing ConfigMap or to create a new one with a list of configurations(i.e with create=true).
# Use "data" to build an integrated ConfigMap from a set of configurations as
# part of this helm chart. An example of setting "data" might be:
# config:
# name: device-plugin-config
# create: true
# data:
# default: |-
# version: v1
# flags:
# migStrategy: none
# mig-single: |-
# version: v1
# flags:
# migStrategy: single
# mig-mixed: |-
# version: v1
# flags:
# migStrategy: mixed
config:
# Create a ConfigMap (default: false)
create: false
# ConfigMap name (either existing or to create a new one with create=true above)
name: ""
# Default config name within the ConfigMap
default: ""
# Data section for the ConfigMap to create (i.e only applies when create=true)
data: {}
# MPS related configuration for the plugin
mps:
# MPS root path on the host
root: "/run/nvidia/mps"아래 리스트는 추후 좀더 확인할 필요가 있음.
# standalone dcgm hostengine
dcgm:
# disabled by default to use embedded nv-hostengine by exporter
enabled: false # GPU의 상태를 직접 관리하지 않고, GPU 메트릭만 수집
repository: nvcr.io/nvidia/cloud-native
image: dcgm
version: 3.3.7-1-ubuntu22.04
imagePullPolicy: IfNotPresent
args: []
env: []
resources: {}
dcgmExporter:
enabled: true # 프로메테우스처럼 외부 노출
repository: nvcr.io/nvidia/k8s
image: dcgm-exporter
version: 3.3.7-3.5.0-ubuntu22.04
imagePullPolicy: IfNotPresent
env:
- name: DCGM_EXPORTER_LISTEN
value: ":9400"
- name: DCGM_EXPORTER_KUBERNETES
value: "true"
- name: DCGM_EXPORTER_COLLECTORS
value: "/etc/dcgm-exporter/dcp-metrics-included.csv"
resources: {}
serviceMonitor:
enabled: false
interval: 15s
honorLabels: false
additionalLabels: {}
relabelings: []
# - source_labels:
# - __meta_kubernetes_pod_node_name
# regex: (.*)
# target_label: instance
# replacement: $1
# action: replace
gfd: # GPU관련 기능을 탐지하여 k8s에 라벨부착.
enabled: true
repository: nvcr.io/nvidia
image: k8s-device-plugin
version: v0.16.2-ubi8
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env:
- name: GFD_SLEEP_INTERVAL
value: 60s
- name: GFD_FAIL_ON_INIT_ERROR
value: "true"
resources: {}
migManager:
enabled: false # rtx3060은 지원하지 않으므로 false
repository: nvcr.io/nvidia/cloud-native
image: k8s-mig-manager
version: v0.8.0-ubuntu20.04
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env:
- name: WITH_REBOOT
value: "false"
resources: {}
# MIG configuration
# Use "name" to either point to an existing ConfigMap or to create a new one with a list of configurations(i.e with create=true).
# Use "data" to build an integrated ConfigMap from a set of configurations as
# part of this helm chart. An example of setting "data" might be:
# config:
# name: custom-mig-parted-configs
# create: true
# data: |-
# config.yaml: |-
# version: v1
# mig-configs:
# all-disabled:
# - devices: all
# mig-enabled: false
# custom-mig:
# - devices: [0]
# mig-enabled: false
# - devices: [1]
# mig-enabled: true
# mig-devices:
# "1g.10gb": 7
# - devices: [2]
# mig-enabled: true
# mig-devices:
# "2g.20gb": 2
# "3g.40gb": 1
# - devices: [3]
# mig-enabled: true
# mig-devices:
# "3g.40gb": 1
# "4g.40gb": 1
config:
default: "all-disabled"
# Create a ConfigMap (default: false)
create: false
# ConfigMap name (either existing or to create a new one with create=true above)
name: ""
# Data section for the ConfigMap to create (i.e only applies when create=true)
data: {}
gpuClientsConfig:
name: ""
nodeStatusExporter:
enabled: false
repository: nvcr.io/nvidia/cloud-native
image: gpu-operator-validator
# If version is not specified, then default is to use chart.AppVersion
#version: ""
imagePullPolicy: IfNotPresent
imagePullSecrets: []
resources: {}
gds:
enabled: false
repository: nvcr.io/nvidia/cloud-native
image: nvidia-fs
version: "2.17.5"
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
args: []
gdrcopy:
enabled: false
repository: nvcr.io/nvidia/cloud-native
image: gdrdrv
version: "v2.4.1-1"
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
args: []
vgpuManager:
enabled: false
repository: ""
image: vgpu-manager
version: ""
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
resources: {}
driverManager:
image: k8s-driver-manager
repository: nvcr.io/nvidia/cloud-native
# When choosing a different version of k8s-driver-manager, DO NOT downgrade to a version lower than v0.6.4
# to ensure k8s-driver-manager stays compatible with gpu-operator starting from v24.3.0
version: v0.6.10
imagePullPolicy: IfNotPresent
env:
- name: ENABLE_GPU_POD_EVICTION
value: "false"
- name: ENABLE_AUTO_DRAIN
value: "false"
vgpuDeviceManager:
enabled: false # 필요시 활성
repository: nvcr.io/nvidia/cloud-native
image: vgpu-device-manager
version: "v0.2.7"
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
config:
name: ""
default: "default"
vfioManager:
enabled: false # 필요시 활성
repository: nvcr.io/nvidia
image: cuda
version: 12.6.1-base-ubi8
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
resources: {}
driverManager:
image: k8s-driver-manager
repository: nvcr.io/nvidia/cloud-native
# When choosing a different version of k8s-driver-manager, DO NOT downgrade to a version lower than v0.6.4
# to ensure k8s-driver-manager stays compatible with gpu-operator starting from v24.3.0
version: v0.6.10
imagePullPolicy: IfNotPresent
env:
- name: ENABLE_GPU_POD_EVICTION
value: "false"
- name: ENABLE_AUTO_DRAIN
value: "false"
kataManager:
enabled: false
config:
artifactsDir: "/opt/nvidia-gpu-operator/artifacts/runtimeclasses"
runtimeClasses:
- name: kata-nvidia-gpu
nodeSelector: {}
artifacts:
url: nvcr.io/nvidia/cloud-native/kata-gpu-artifacts:ubuntu22.04-535.54.03
pullSecret: ""
- name: kata-nvidia-gpu-snp
nodeSelector:
"nvidia.com/cc.capable": "true"
artifacts:
url: nvcr.io/nvidia/cloud-native/kata-gpu-artifacts:ubuntu22.04-535.86.10-snp
pullSecret: ""
repository: nvcr.io/nvidia/cloud-native
image: k8s-kata-manager
version: v0.2.1
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env: []
resources: {}
sandboxDevicePlugin:
enabled: true
repository: nvcr.io/nvidia
image: kubevirt-gpu-device-plugin
version: v1.2.9
imagePullPolicy: IfNotPresent
imagePullSecrets: []
args: []
env: []
resources: {}
ccManager:
enabled: false
defaultMode: "off"
repository: nvcr.io/nvidia/cloud-native
image: k8s-cc-manager
version: v0.1.1
imagePullPolicy: IfNotPresent
imagePullSecrets: []
env:
- name: CC_CAPABLE_DEVICE_IDS
value: "0x2339,0x2331,0x2330,0x2324,0x2322,0x233d"
resources: {}
node-feature-discovery:
enableNodeFeatureApi: true
priorityClassName: system-node-critical
gc:
enable: true
replicaCount: 1
serviceAccount:
name: node-feature-discovery
create: false
worker:
serviceAccount:
name: node-feature-discovery
# disable creation to avoid duplicate serviceaccount creation by master spec below
create: false
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
config:
sources:
pci:
deviceClassWhitelist:
- "02"
- "0200"
- "0207"
- "0300"
- "0302"
deviceLabelFields:
- vendor
master:
serviceAccount:
name: node-feature-discovery
create: true
config:
extraLabelNs: ["nvidia.com"]
# noPublish: false
# resourceLabels: ["nvidia.com/feature-1","nvidia.com/feature-2"]
# enableTaints: false
# labelWhiteList: "nvidia.com/gpu"Kubernetes 부분 설정
Node Taint설정
노드 리스트를 조회하고 gpu관련 리소스가 배포될 노드를 제한하기 위하여 Taint설정을 합니다.
쿠버네티스의 특정 노드에 Taint를 추가하여, GPU 노드에서 일반 워크로드가 스케줄링되지 않도록 제어하는 역할을 합니다. 이를 통해 GPU가 필요 없는 애플리케이션이 GPU 노드에 배치되지 않게 하여, GPU 자원을 최적화할 수 있습니다.
Kubectl get no
kubectl taint node gk8s-worker01 nvidia.com/gpu=present:NoSchedule
Toleration 설명(참고자료)
Taint를 설정하고 pod에 사용할 toleration을 설정을 하게되면 만날수 있는 내용을 설명합니다.
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists" # Exsts, Equal(default)
effect: "NoSchedule"operator의 옵션은 Exists와 Equal이 있습니다.
Exists는 key와만 맞으면 배포를 하게되고,
Equal은 key와 value가 모두 만족해야 배포되게 됩니다.
(단, effect는 Taint와 Toleration을 맞추어 주는 것이 좋습니다. 정상동작 하지 않을 수 있음.)
Taint 삭제방법(옵션)
테인트 삭제시 아래명령어를 이용합니다.
kubectl taint node gk8s-gpu nvidia.com/gpu=present:NoSchedule-k8s namespace생성
kubectl create ns gpu-operator권한설정
NVIDIA GPU Operator는 GPU 드라이버 설치, NVIDIA 컨테이너 툴킷 설치 등 호스트 OS의 커널과 직접 상호작용하는 작업이 필요합니다. 이때, privileged 모드가 필요합니다.
privileged모드는 컨테이너가 호스트의 모든 장치에 접근할 수 있게 하여 GPU, 네트워크 장치 등을 사용할 수 있게 합니다.
만약privileged모드를 사용하지 않으면, GPU Operator가 정상적으로 작동하지 않거나 필요한 리소스에 접근하지 못할 수 있습니다.
kubectl label --overwrite ns gpu-operator pod-security.kubernetes.io/enforce=privileged라벨 삭제시(옵션)
kubectl label --overwrite ns gpu-operator pod-security.kubernetes.io/enforce-적용 전 네임스페이스 라벨 조회내용.

적용 후 네임스페이스 라벨 조회내용.

Helm Deploy
helm install gpu-operator nvidia/gpu-operator -n gpu-operator --create-namespace -f /config/workspace/opensource-test/gpu-operator/gpu-operator_v24.6.2/values.yaml
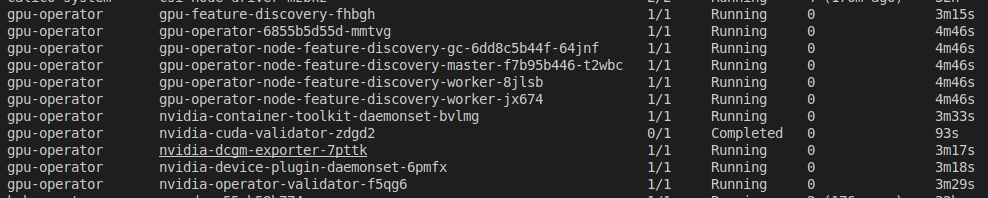
만약에 gpu-operator-node-feature-discovery-gc파드가 계속 pending상태라면?
마스터와 gpu노드 1개로 구성하여 테스트 환경을 구성하면 gc가 배포되지 않을 수 있다. Taint영향으로 인한 현상으로 Deploy에 toleration을 추가하면된다.
kubectl edit -n gpu-operator deployments.apps gpu-operator-node-feature-discovery-gc spec:
template:
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Equal테스트 jupyter노트북 배포
apiVersion: v1
kind: Service
metadata:
name: tf-notebook
labels:
app: tf-notebook
spec:
type: NodePort
ports:
- port: 80
name: http
targetPort: 8888
nodePort: 30001
selector:
app: tf-notebook
---
apiVersion: v1
kind: Pod
metadata:
name: tf-notebook
labels:
app: tf-notebook
spec:
securityContext:
fsGroup: 0
containers:
- name: tf-notebook
image: tensorflow/tensorflow:latest-gpu-jupyter
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 8888
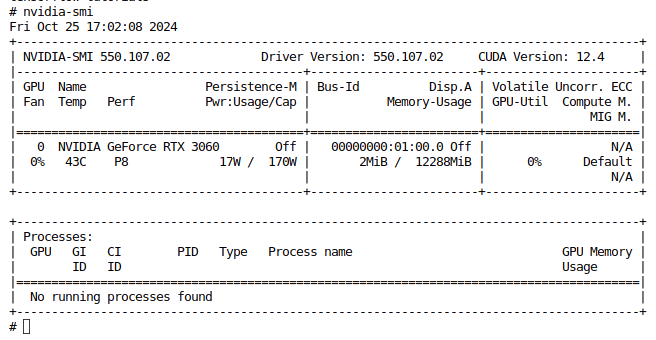
name: notebook접속 후 터미널을 생성하여 gpu연동이 되는지 확인합니다.